High-performance PC SoCs too
Qualcomm introduced Prime core clocked rest from the cluster with Snapdragon 865, and Huawei had two higher clock performance cores in Kirin 990. With that in mind, ARM has introduced the Cortex-X custom program. The result is up to 30 percent peak performance compared to previous generation Cortex A77 cores.
Cortex X is a custom silicon designed on a completely different CPU architecture from Cortex, but it has a new and improved core, more insts, and Mops more NEON engines and more cache.
Chris Abernathy, distinguished engineer, Client Line of Business at ARM, was very clear as he mentioned that this core is designed for performance and short bursts of extreme performance and not for sustainable performance. The main goal is to turn the core up, get the job done, and shut it down as fast as possible to prevent unnecessary energy consumption.
Before we dig deeper, you can expect to see Cortex-X1 in future 2021 high-end smartphones – possibly late 2020 too – and PC like devices such as the next-generation 8CX from Qualcomm. Of course, ARM doesn’t comment or announce products for its customers, but it is clear that the Cortex-X1 was created to pressure Intel on the notebook and foldable notebook side.
ARM came up with the Corex-X custom program, and a custom license allows partners to customize and differentiate over the standard Cortex products. The new core will follow the ARM Cortex brand, and it will only be available to Cortex-X customers.
Cortex-X1
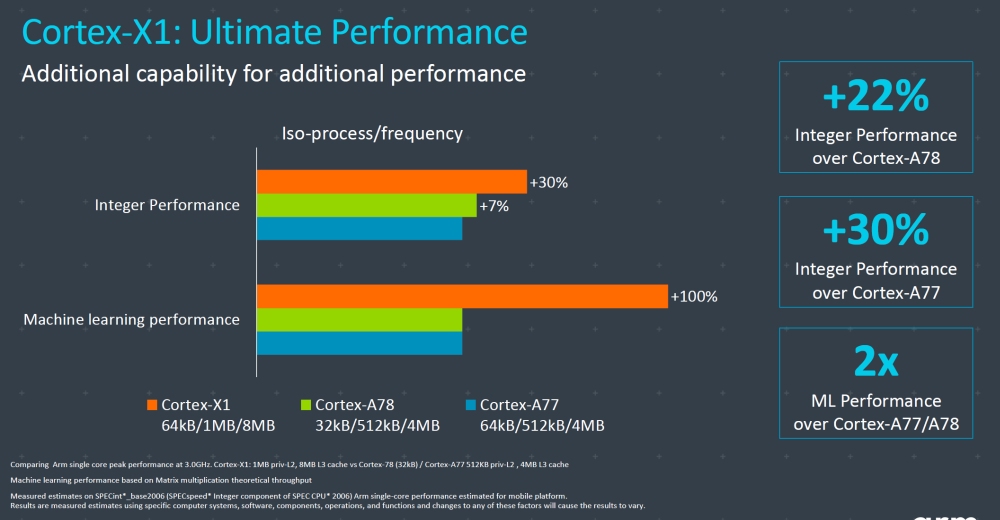
The first of many to come Coretex-X custom offers 30 percent peak performance over Cortex A77. The company was comparing a single core peak performance at 3.0GHz. Cortex-X1: 1MB private L2, 8MB L3 cache vs Cortex-A77: 512KB private L2 , 4MB L3 cache in SPECint*_base2006.
Compared to Cortex-A78, the Cortex-X1 comes with 5 Insts and 8 Mops (4 and 6 with A78), four 128b NEON (A78 has two), 64GB L1 cache (The A78 has 32kb or 64kb) and up to 1 MB L2 cache (The A78 has half of it). Finally, the L3 cache goes up to 8MB, double the A78.
Cortex A55 cores are also supported, and ARM expects customers to use at least one Cortex-X1 core and mix it with a cluster of Cortex-A78 for sustained performance and Cortex-A55 for low power usage.
The 30 percent increase delta of Cortex-X 64kB L1, 1MB L2, and 8MB L3 comes in integer performance against Cortex-A77 64kB/512kB/4MB. When comparing Cortex-A78 32kB/512kB/4MB to X1, the performance increase stops at 22 percent, while Cortex-A78 beats A77 by seven percent.
Machine learning performance on Cortex-X1 scores twice that of the Cortex-A77 or A78. Machine learning performance is based on Matrix multiplication theoretical throughput.

ARM Custom X1 Silicon
ARM sees customers using four Cortex-*A78 and gaining 20 percent more sustained performance compared to Cortex-A77 using fifteen percent less cluster area.
The second use case scenario is a single Cortex-X1 (just like Prime core with Snapdragon 865), three Cortex-A78 for sustained performance, four Cortex-A55 for low power operations and massive 8MB L3 cache. Arm estimates 30 percent peak performance against A77 based silicon, and this will cost customers an additional 15 percent of cluster area. Since Cortex-X1 is aiming at high-end performance phones and notebooks, these guys will be willing to spend more silicon to gain such a performance.
Cortex-X1 comes with a 50 percent larger L0 BTB capacity with 96 entries (zero-cycle bubble taken-branch latency). It has increased fetch bandwidth available with five instruction fetch from the instruction cache and 8 Mop fetch from the Mop cache.
Furthermore, it comes with two times Mop cache over Cortex-A77, 3K entries, for increased coverage.
Additional performance comes by pushing the limits of width and depth of a core. Cortex-X1 has a 33 percent increase in dispatch bandwidth with up to 8-instr/cycle and a 40 percent increase in out-of-order window size with 224 entry instruction window and expose more parallelism in code.
It also offers two times FP/ASIMD execution bandwidth 4x128b total bandwidth offering up to two times ML performance.
ARM has double available L1-D L2 bandwidth and maximal L2 capacity for large footprint applications. It offers a 33 percent increase in window growth for in-flight loads and stores and 66 percent larger L2-TLB capacity 2K entries.
Customers such as Qualcomm, Samsung, Huawei, and Arm won’t just tweak up to Cortex-A core for high-performance burst; now, the Cortex-X supporters will have one additional rather powerful core to tweak. ARM didn’t want to comment on who is part of its custom program.